三维重建
三维重建(3D Reconstruction):从一堆二维图像中恢复物体的三维结构,并进行渲染,最终在计算机中进行客观世界的虚拟现实的表达。
客观世界中的物体都是三维的,真实地描述和显示客观世界中的三维物体是计算机图形学研究的重要内容。三维重建又是计算机图形图像的核心技术之一,应用领域非常广泛。
百度上对于三维重建给出的定义是指对三维物体建立适合计算机表示和处理的数学模型,是在计算机环境下对其进行处理、操作和分析其性质的基础,也是在计算机中建立表达客观世界的虚拟现实的关键技术。
目前,大家大多在研究模型识别,但这只是计算机视觉的一部分,真正意义上的计算机视觉要超越二维,感知到三维环境。我们生活在三维空间里,要做到更高效的交互和感知,也须将世界恢复到三维。
技术特点
三维重建所拥有的特点在于:
- 较之二维空间来说更具备纵深感。三维空间内可以展示物体以及人物场景的立体性,做到与真是世界一致的效果。
- 具备仿真能力。可以高度还原人物的细节与真实性,完成2D空间内无法实现的细致表情与动作。
- 可以模拟物理特性,创造模拟出碰撞、飘动、挥动、流动等特性,更加具备真实性。
- 自然的处理光效,画面更具真实性。
三维重建的整体流程
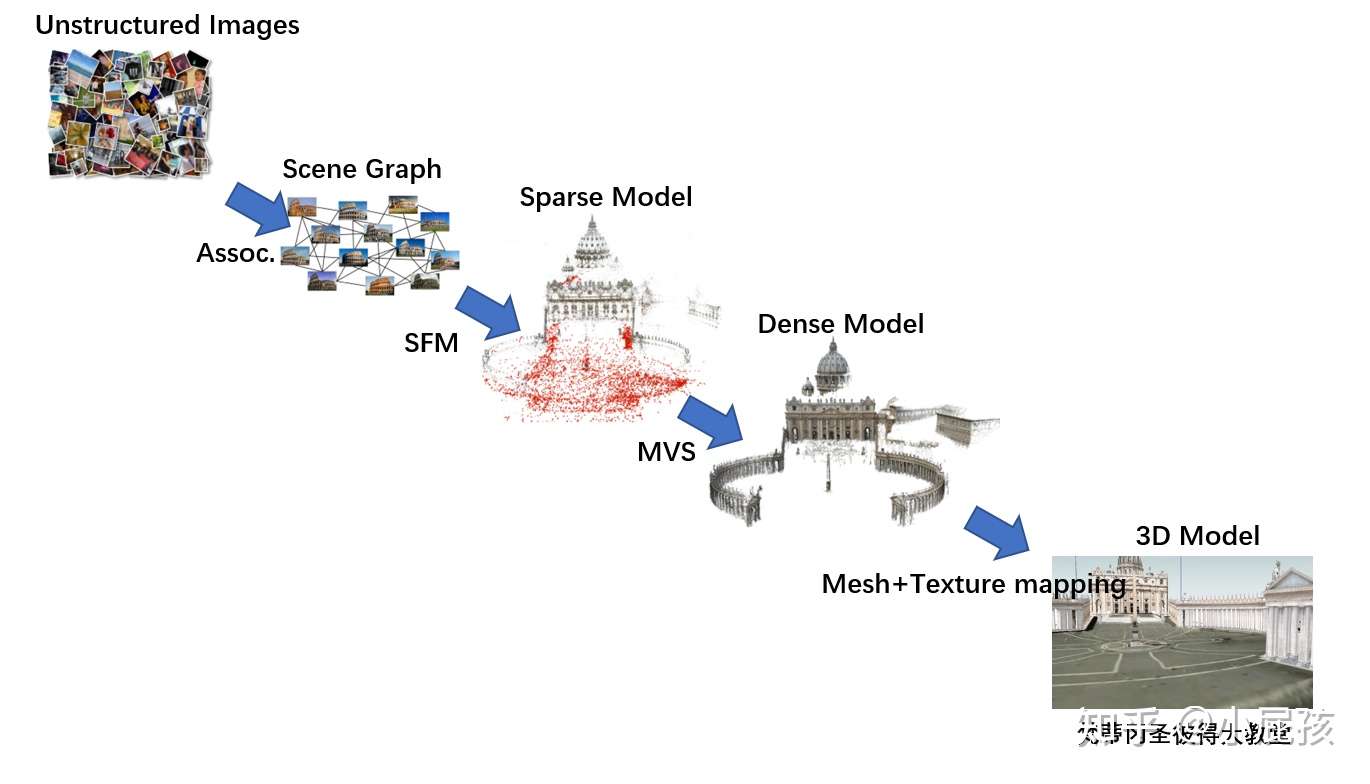
- 输入无序图像 Unstructured Images
- 图像对齐(Assoc.),筛选图像,构建场景图(也称为连接图)。
- 稀疏重建(Structure from Motion,SFM),生成稀疏的3D点云结构,该步骤的贡献是建立统一的坐标系,确定 了重建物体的尺寸,提供可靠的2D-3D多对一的匹配点对。
- 稠密重建(Multiple View Stereo,MVS),生成稠密的3D点云结构,该步骤的贡献生成稠密的点云。
- 表面重建(Mesh,Model Fitting),稠密点云转化为网格(mesh)。
- 纹理重建(Texture Mapping) ,纹理贴图,即对网格进行纹理坐标映射,进行贴纹理。
- 可视化渲染
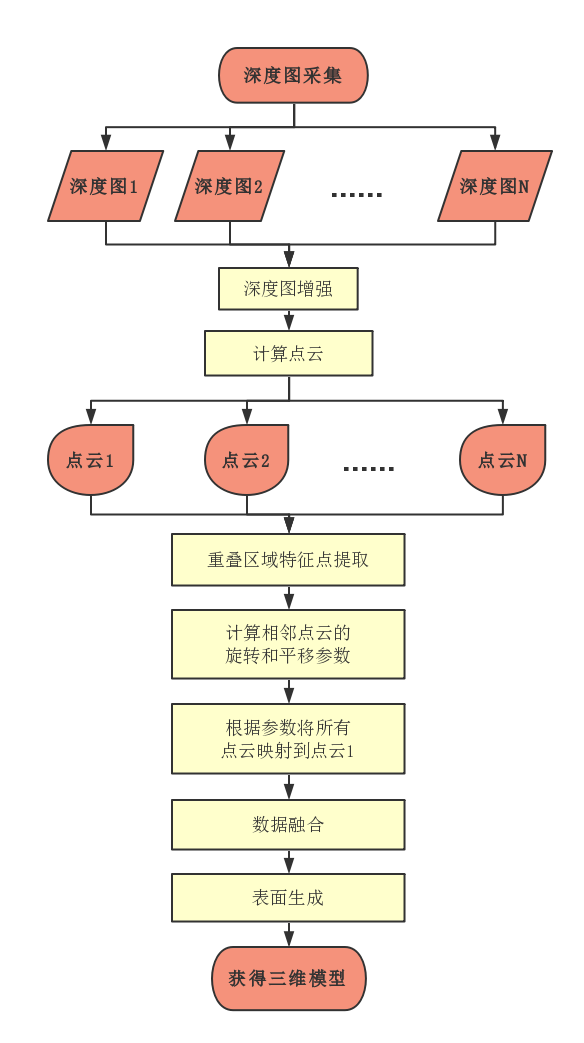 受到设备分辨率等限制,采集到的深度信息也存在着许多缺点。为了获得更好的三维模型,必须对深度图像进行去噪和修复等图像增强过程。
受到设备分辨率等限制,采集到的深度信息也存在着许多缺点。为了获得更好的三维模型,必须对深度图像进行去噪和修复等图像增强过程。
对于多帧通过不同角度,位置拍摄的景物图像,各帧之间包含一定的公共部分,首先需要提取出这些部分中有代表的特征点并一一对应,从而为接下来的参数估计做准备。
为了利用深度图像进行三维重建,需要对图像进行分析,求解各帧之间的变换参数(如使用经典的ICP方法)。深度图像的配准是以场景的公共部分为基准,计算出相应的平移向量与旋转矩阵,从而把不同时间、角度、照度获取的多帧图像叠加匹配到统一的坐标系中,同时消除冗余信息。
点云配准除了会制约三维重建的速度,也会影响到最终模型的精细程度和全局效果。因此必须提升点云配准算法的性能。
通过上面的步骤可以得到完整的三维点云,但是需要对点云进行三角剖分获得三角面片,才能形成最终的三维模型。
常见的三维表示方法
计算机屏幕本身是二维平面的,我们之所以能欣赏到真如实物般的三维图像,是因为显示在计算机屏幕上色彩和灰度的不同而产生错觉,将二维屏幕感知为三维环境。
由色彩学可知,三维物体边缘的凸出部分一般显高亮度色,而凹下去的部分由于受光线的遮挡而略显暗色,加之人眼也有近大远小的成像特性,就会形成3D立体感。
对于如何在计算机中表示出3D模型效果,根据不同的使用需求有不同的表示方法,基本可以分为四类,深度图(Depth Map)、点云(Point Cloud)、体素(Voxel)和网格(Mesh)。
深度图(Depth Map)
深度图是一张2D图片,每个像素都记录了从视点(Viewpoint)到遮挡物表面(遮挡物就是阴影生成物体)的距离,相当于只有三维信息里Z轴上的信息,这些像素对应的顶点对于观察者而言是“可见的”。
体素(Voxel)
体素或立体像素是体积像素(VolumePixel)的简称,是模型数据于三维空间上的最小单位,是一种规则数据。
体素概念上类似于二维图像中的像素,其本身并不含有空间中位置的数据(即它们的座标),然而却可以从它们相对于其他体素的位置来推敲。
网格(Mesh)
多边形网格(Polygonmesh)是三维计算机图形学中表示多面体形状的顶点与多边形的集合,是一种非规则结构数据。这些网格通常由三角形、四边形或者其它的简单凸多边形组成。
其中,最常用的是三角网格,三角网格通常需要存储三类信息:
- 顶点:每个三角网格都有三个顶点,各顶点都有可能和其他三角网格共享。
- 边:连接两个顶点的边,每个三角网格有三条边。
- 面:每个三角网格对应一个面,我们可以用顶点或边的列表来表示面。
点云(Point Cloud)
点云是指以点的形式记录的数据。每一个点包含了丰富的信息,包括三维坐标X、Y、Z、颜色、分类值、强度值、时间等等。点云可以将现实世界原子化,通过高精度的点云数据可以还原现实世界。
选哪个作为我们常用的3D模型表示呢?
根据介绍我们可以知道Voxel,受到分辨率和表达能力的限制,会缺乏很多细节;Point Cloud,点之间没有连接关系,会缺乏物体的表面信息;相比较而言Mesh的表示方法具有轻量、形状细节丰富的特点。
三维重建技术
三维重建技术上大体可分为接触式和非接触式两种。其中,较常见的是非接触式中基于主动视觉的如激光扫描法、结构光法、阴影法和Kinect技术等,和基于机器学习的如统计学习法、神经网络法、深度学习与语义法等。
激光扫描法
激光扫描法其实就是利用激光测距仪来进行真实场景的测量。
首先,激光测距仪发射光束到物体的表面,然后,根据接收信号和发送信号的时间差确定物体离激光测距仪的距离,从而获得测量物体的大小和形状。
结构光法
结构光法的原理是:
- 首先,按照标定准则将投影设备、图像采集设备和待测物体组成一个三维重建系统;
- 其次,在测量物体表面和参考平面分别投影具有某种规律的结构光图;
- 然后,再使用视觉传感器进行图像采集,从而获得待测物体表面以及物体的参考平面的结构光图像投影信息;
- 最后,利用三角测量原理、图像处理等技术对获取到的图像数据进行处理,计算出物体表面的深度信息,从而实现二维图像到三维图像的转换。
按照投影图像的不同,结构光法可分为:点结构光法、线结构光法、面结构光法、网络结构光和彩色结构光。
阴影法
阴影法是一种简单、可靠、低功耗的重建物体三维模型的方法。
这是一种基于弱结构光的方法,与传统的结构光法相比,这种方法要求非常低,只需要将一台相机面向被灯光照射的物体,通过移动光源前面的物体来捕获移动的阴影,再观察阴影的空间位置,从而重建出物体的三维结构模型。
Kinect技术
Kinect传感器是最近几年发展比较迅速的一种消费级的3D摄像机,它是直接利用镭射光散斑测距的方法获取场景的深度信息,Kinect传感器如下图所示。
Kinect传感器中间的镜头为摄像机,左右两端的镜头被称为3D深度感应器,具有追焦的功能,可以同时获取深度信息、彩色信息、以及其他信息等。
Kinect在使用前需要进行提前标定,大多数标定都采用张正友标定法。
Pixel2Mesh
Pixel2Mesh(Generating3D Mesh Models From Single RGB Images):
- 首先给定一张输入图像:InputImage。
- 为任意的输入图像都初始化一个固定大小的椭球体(三轴半径分别为0.2、0.2、0.8m)作为其初始三维形状:Ellipsoid Mesh。
- 整个网络可以分成上下两个部分:图像特征提取网络和级联网格变形网络。
- 上面部分负责用全卷积神经网络(CNN)提取输入图像的特征。
- 下面部分负责用图卷积神经网络(GCN)来提取三维mesh特征,并不断地对三维mesh进行形变,逐步将椭球网格变形为所需的三维模型,目标是得到最终的飞机模型。
- 注意到图中的PerceptualFeature Pooling层将上面的2D图像信息和下面的3Dmesh信息联系在了一起,即通过借鉴2D图像特征来调整3D mesh中的图卷积网络的节点状态。这个过程可以看成是Mesh Deformation。
- 还有一个很关键的组成是GraphUnpooling。这个模块是为了让图节点依次增加,从图中可以直接看到节点数是由156-->628-->2466变换的,这其实就Coarse-To-Fine的体现。
对欧几里得空间中一维序列的语音数据和二维矩阵的图像数据我们会分别采取RNN和CNN两种神经网络来提取特征,那GCN其实就是针数据结构中另一种形式图的结构做特征提取。GCN在表示3D结构上具有天然的优势。
受深度神经网络的限制,此前的方法多是通过Voxel和Point Cloud呈现,而将其转化为Mesh并不是一件易事,Pixel2Mesh则利用基于图结构的神经网络逐渐变形椭圆体来产生正确的几何形状。
该算法所应用的领域是物体的3D模型重建,可以期待将其扩展为更一般的情况,如场景级重建,并学习多图像的多视图重建。
应用场景
城市规划、测绘系统、高精地图、虚拟仿真、文物保护、VR/AR导航。
发展趋势
深度学习已经关注了重建领域,主要关注的是形状补全和重建。其中个人认为比较有代表性的是来自于Facebook Research 的DeepSDF。
但是大多数的数据驱动方法都是通过形成对训练数据的隐式空间来进行重建,所以重建相当于从已知的训练知识中通过隐空间插值的方法来获得重建数据。
虽然可以通过神经网络获得有代表性的特征表示,但是这类方法的鲁棒性和实际可用性相对来说会比较局限。
开源框架
- Meshroom: https://github.com/alicevision/meshroom
- OpenMVG: https://github.com/openMVG/openMVG
- Colmap: https://github.com/colmap/colmap
- OpenSfM:https://github.com/mapillary/OpenSfM
- OpenMVS:https://github.com/cdcseacave/openMVS
- Bundler: https://github.com/snavely/bundler_sfm
- MVE:https://github.com/simonfuhrmann/mve
- SFMedu:https://github.com/jianxiongxiao/SFMedu
- TeleSculptor:https://github.com/Kitware/TeleSculptor
- TheiaSfM:https://github.com/sweeneychris/TheiaSfM
- Opengv: https://github.com/laurentkneip/opengv